总组织
磁盘的最基本存储单位不是字节,而是块 (block)。常用的块大小为 4KB。
一个组织在该磁盘上的文件系统:
- 数据区域 (data region):占据绝大部分的块。毕竟磁盘本身就是数据的存储设备!
- 超级块 (superblock):通常在第 0 块。
- 数据位图 (data bitmap)
- inode 位图 (inode bitmap)
- inode 表 (inode table)
超级块
超级块存储该文件系统本身的元数据。
- 文件系统标识符
- 有多少 inode?有多少数据块?
- inode 位图,inode 表,数据位图的地址?
- 根目录的 inode?
超级块很重要,因此文件系统会在存储设备里做几个备份。
inode
上一节我们说到 inode number 是文件的独特标识符。
inode 本身是文件的元数据单位,又被称为文件管理块 (file control block, FCB)。它存储了对应文件的:
- 类型
- 大小
- 所有者 (ownership)
- 权限 (permission)
- 最后访问时间
- 硬链接的引用计数
- 文件内容的地址:即该文件所有的数据块地址。如何索引?
有三种方式。
多级索引
多级索引 (multi-level index) 在 inode 中存储多个直接指针 (direct pointer),少数间接指针 (indirect pointer) ,包括次级间接指针 (double indirect pointer) 与三级间接指针 (triple indirect pointer)。
间接指针指向的是一个专门存储地址的数据块。假设一个数据块大小为 $a$,每个数据块可以存储 $n$ 个数据块的地址,那么一个 $k$ 级间接指针可以覆盖 $an^k$ 大小的磁盘空间。
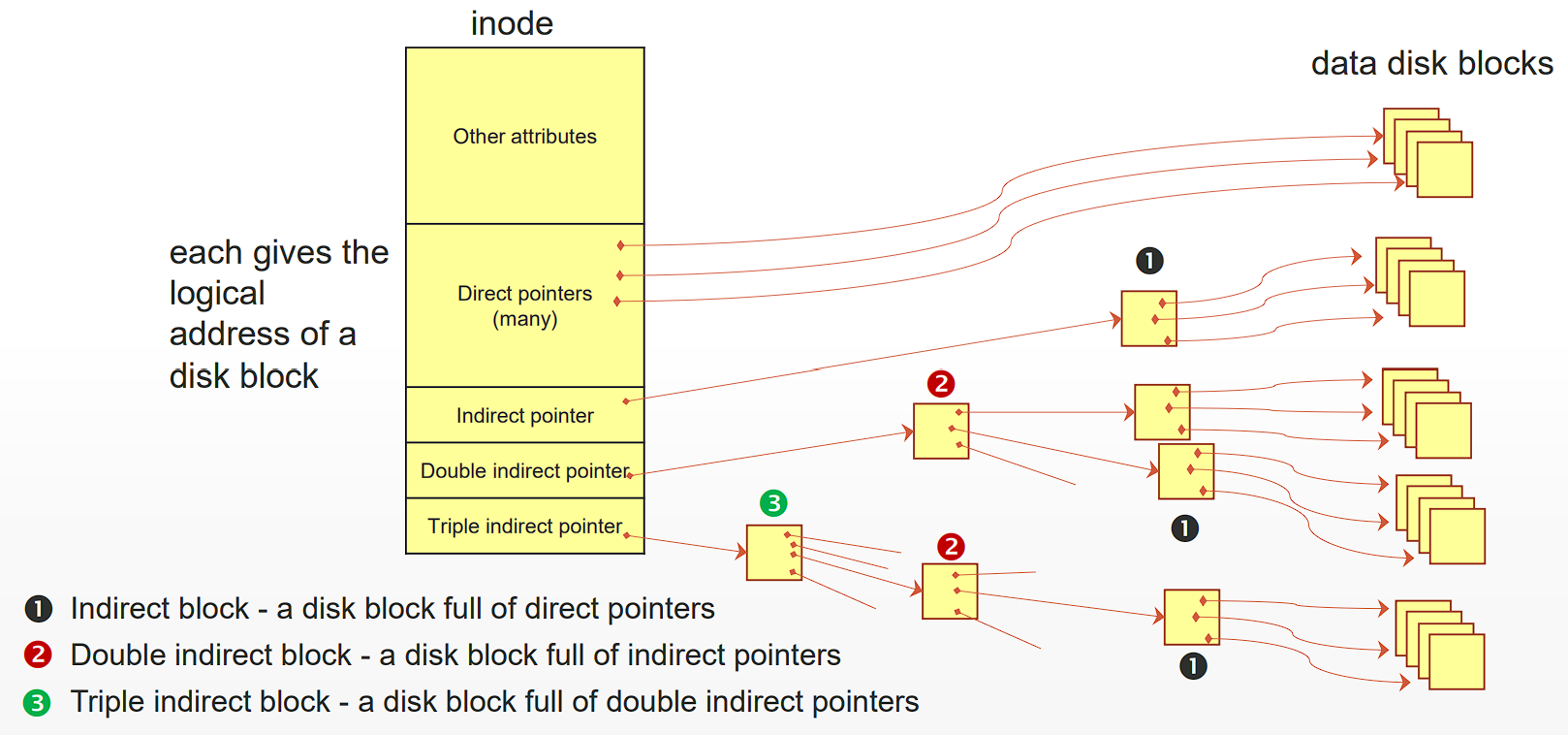
直接指针可以索引多数文件:只有那些较大的文件才会涉及到间接指针。
链表索引
链表索引 (linked-list index) 在 inode 中存储一个指针,指向该文件的第一个数据块。
同时,第 $n$ 个数据块中将会储存指向第 $n+1$ 数据块的指针。
表索引
和链表索引不同的是,表索引 (tabular index) 单独拉出一张表来记录每个数据块的下一个数据块,而不是把这个信息维护在数据块里面。
表中记录的是数据块的编号而不是实际的指针。
- 第 2 个数据块的下一个数据块是 5,那么 $T[2]=5$
表可以被缓存从而提高搜索与遍历的效率。
inode 表
文件的 inode 存在哪里呢?当然是 inode 表 (inode table)!
给定文件的标识符 inode number,可以通过查 inode 表获得它的 inode。
硬盘中被地址索引 (addressable) 的单位是扇区 (sector)。假设 inode 表中每个 block 存储一个 inode,计算给定 inode number 所在的扇区:
1 | blk = (inumber * sizeof(inode_t)) / blockSize; |
空闲空间管理
inode 位图 (inode bitmap) 的每一位标识对应的 inode 在 inode 表中是空闲的还是正在被使用的。这个简单的数据结构用于辅助 inode 的分配与释放。
数据位图 (data bitmap) 起到同样的作用,每一位标识对应的数据块是空闲的还是被文件占用的($x$ 个数据块,$x$ 位,数据位图占用 $x/8$ 字节)。
空闲链表索引
数据位图的替代。
和链表索引一样,只不过空闲链表 (free link-list) 索引的是空闲的数据块,链表索引的是某个文件拥有的数据块。
空闲块表索引
空闲块表是一个由块组织而成的空闲空间索引。
假设每个块可以存储 $n$ 个数据块的地址,那么空闲块表中的每个块:
- 前 $n-1$ 项,每项指向数据区域的一个空闲块
- 第 $n$ 项,指向空闲块表中的下一个块
缺点:数据分散在不连续的块上。对于硬盘而言,I/O 效率会大大降低。
阅读
Chapter 40 – File System Implementation, OSTEP,
http://pages.cs.wisc.edu/~remzi/OSTEP/file-implementation.pdf