把实际延迟 $d_{abs}$ 除以一个基准时间常数 $\tau$,得到无量纲的归一化延迟 $d$。$d$ 是工艺无关的,因此可以作为比较电路结构优劣的标准。
$$
d=\frac{d_{abs}}{\tau}
$$
$d$ 由两部分组成:
$$
d=f+p
$$
其中 $f$ 是努力延迟(effort delay),取决于门的复杂度与扇出,是门实际在努力为负载电容充放电产生的延迟;$p$ 是寄生延迟(parasitic delay),是门内部的寄生电容充放电产生的延迟。当 $f=0$(无负载电容时),$d$ 函数的截距(interception)即为 $p$。
$$
f=gh
$$
$g$ 是逻辑努力(logical effort),表征门的复杂度。而电气逻辑(electrical effort)则表征门的扇出,其计算方式是负载(输出)电容与门输入电容的比值:
$$
h=\frac{C_{out}}{C_{in}}
$$
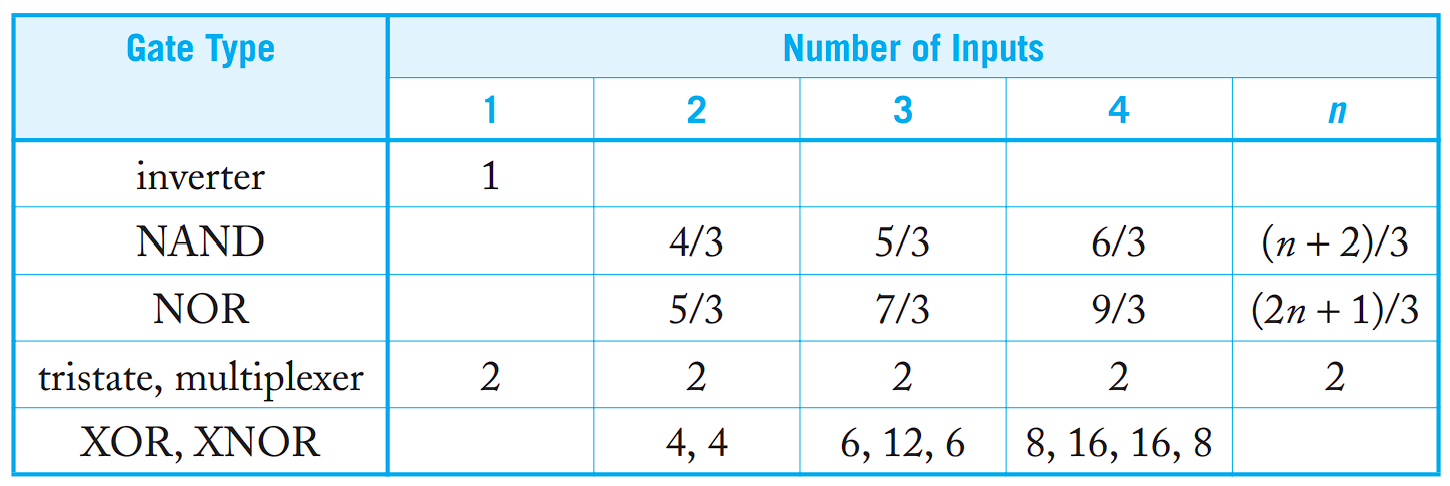
逻辑努力
如何表征一个逻辑门的复杂度?选取标准反相器作为归一化的标准。一个逻辑门越复杂,它的输入电容越大。定义逻辑努力 $g$ 为:
显然标准反相器的逻辑努力为 $1$。
计算逻辑努力时,仅需:
- 第一步:将门按照标准反相器的有效电阻(PUN 与 PDN 分别为 $R$)尺寸化(调整各部分晶体管的宽度使其 PUN 与 PDN 分别为 $R$,晶体管宽度与其有效电阻成反比),使其输出电流与标准反相器一致
- 第二步:计算该门输入晶体管的宽度之和,除以 $3$ 得到 $g$(晶体管宽度与其电容成正比,标准反相器的输入晶体管宽度之和为 pMOS $2$ + nMOS $1=3$)
寄生延迟
粗略估计寄生延迟的方法:输出节点 $Y$ 的扩散电容与 $3C$ 的比值(归一化,标准反相器输出节点处的扩散电容为 $3C$),单位为 $\tau$。
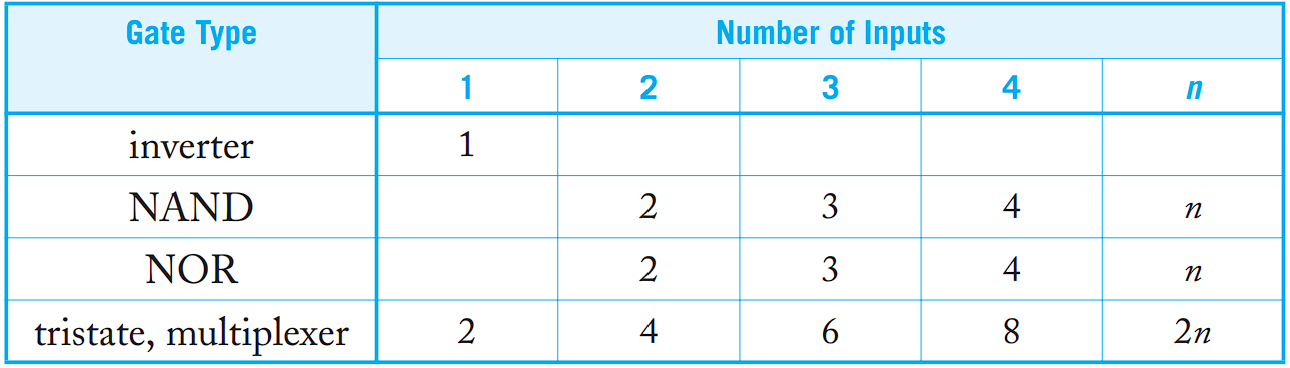
这忽略了门内部的扩散电容,比如串联 MOS 中夹着的(共享)扩散电容。因此有时会使用 Elmore 延迟模型来更准确的计算寄生延迟。
最小化路径上的努力延迟
计算多级路径(multistage path)中各级的逻辑努力与电气努力。
关注的路径(path of interest)的逻辑努力:
$$
G=\prod g_i
$$
路径电气努力(在这个定义中就考虑旁支负载 $B$):
$$
H=\prod h_i=\prod \frac{C_{out, i}}{C_{in, i}}
$$
路径努力(path effort):
$$
F=GH
$$
注意只要路径的输入电容与负载电容不变,路径努力 $F$ 就与该路径上电容的尺寸无关。
考虑路径的总延迟 $D$:
$$
\begin{aligned}
D&=\sum d_i=D_F+P \\
D_F&=\sum f_i \\
P&=\sum p_i
\end{aligned}
$$
路径努力 $F=\prod f_i$ 为一定值,为最小化路径努力延迟(path effort delay)$D_F=\sum f_i$,每个 $f_i$ 均应相等。因此路径上每一级的最优努力延迟应为:
$$
\hat{f}=g_ih_i=F^{1/N}
$$
从后往前(路径终点的负载电容不变且已知)逐个计算第 $i$ 级门的最优输入电容:
$$
\hat{f}=g_ih_i=g_i\frac{C_{out, i}}{C_{in, i}} \\
\Longrightarrow C_{in, i}=\frac{g_iC_{out, i}}{\hat{f}}
$$
调整对应逻辑门的尺寸(宽度)以达到最优输入电容。
例题见 Lecture 5 pp. 28-32。
最优级数(一)
考虑一条 64 位的数据通路(datapath),被若干个单位反相器驱动。最优级数是多少?
单位反相器的逻辑努力 $g_i=1$,路径的逻辑努力 $G=\prod g_i=1$
路径的电气努力 $F=64\prod(1/1)=64$
所以有 $D_F=F^{1/N}$
单位反相器的寄生延迟 $p_{inv}(i)\approx 1$,路径的寄生延迟 $P=\sum p_{inv}(i)=N$
所以路径的总延迟可以表示为关于级数 $N$ 的函数 $D=N(64)^{1/N}+N$
最优级数(二)
第二个场景,有一个 $n_1$ 级,路径努力为 $F$ 的逻辑块(logic block),在其末端再加若干个单位反相器,最优总级数 $N$ 是多少?
增加反相器并不会改变路径的逻辑努力 $G$ 与电气努力 $F$,但会增加路径的寄生延迟 $P$。新路径的最佳总延迟为:
$$
D=NF^{1/N}+\sum_{i=1}^{n_1} p_i+(N-n_1)p_{inv}
$$
$D(N)$ 先降后升,令导数 $=0$,求最小化 $D$ 的极值点 $\hat{N}$:
$$
\begin{aligned}
\frac{dD}{dN}=-F^{1/N}\ln F^{1/N}+F^{1/N}+p_{inv}&=0 \\
\Rightarrow p_{inv}+\rho(1-\ln \rho)&=0 \text{ where }\rho=F^{1/\hat{N}}
\end{aligned}
$$
该式无形式解。若忽略反相器的寄生延迟($p_{inv}=0$),有级努力(stage effort)$\rho=e$;通常地,有 $p_{inv}=1$,此时方程的数值解为 $\rho=3.59$。
使得总延迟最小的最佳级数为 $\hat{N}=\log_{\rho} F$。
敏感度分析
敏感度(sensitivity):当采用的级数偏离最佳值时,延迟会对这种偏离有多敏感?
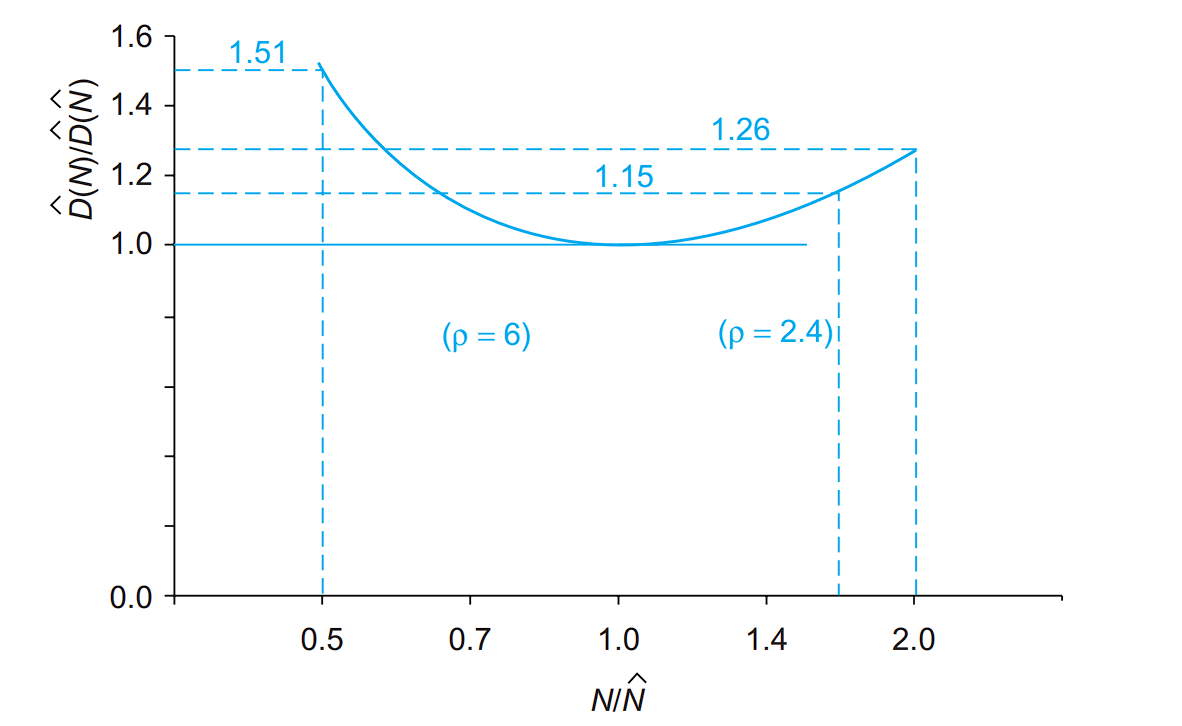
级数在理论最佳级数的 $2/3$ 到 $3/2$ 之间(相应的,级努力在 $2.4\sim 6$ 范围内),延迟都能保持在最小延迟的 $15\%$ 以内。工程上常取级努力 $\rho=4$,便于快速计算合适的级数。这解释了为何 4 扇出反相器是一个代表性的逻辑门延迟单元。
一个例子:解码器设计
设计一个 4:16 解码器(decoder)
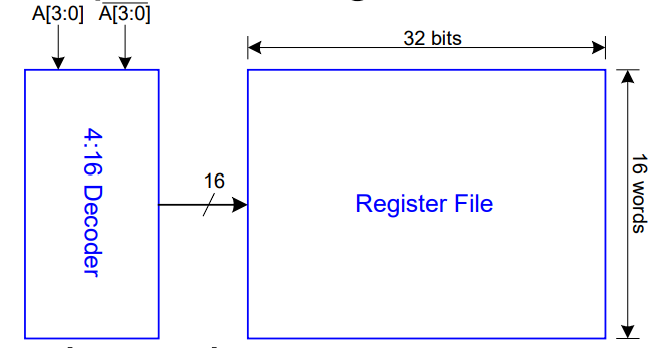
- 16 个 word register file
- 每个 word 有 32 位
- 每一位负载 3 个单位晶体管(2 个单位访问晶体管电容与 1 个布线电容)
- 输入 $A[3:0]$ 自带补信号
- 每个输入驱动最多 10 个单位晶体管
一个 $2^N$ 输出的解码器,可以用 $2^N$ 个 $N$ 输入 NAND 门来实现。做法是:对每个输入位,同时提供它的原信号和反相信号;对每一种可能的输入组合,构造一个对应的 NAND 门。该门的每个输入要么接原信号,要么接反相信号,使其只在这一种组合下所有输入为 $1$。这样,每个 NAND 门唯一对应一个地址组合,从而产生 $2^N$ 条互斥的(低有效)选择信号。
那么,某一条(输入)地址线 address line 将会驱动 16 个字线 word line 的一半(另一半由反相信号地址线驱动),所以电路路径上的某处一定有一个 8 路扇出。
一条字线控制 $32$ 位的 word,共 $32\times 3=96$ 个单位的电容。
那么对于一条驱动 10 单位晶体管的地址线输入,其电气努力约为:
$$
H=8\times 96 / 10=76.8
$$
忽略逻辑努力(令 $G=1$,即理想驱动器,延迟不受门逻辑功能的复杂度影响),有路径努力:
$$
F=GH=76.8
$$
取级努力 $\rho=4$,级数 $N=\log_4 F=3.1$;因此可以尝试 3 级设计。
3 级设计中各级的输入电容与门宽度计算见 Lecture 5 pp. 46。
由此可见逻辑努力的一个重要局限:先有鸡还是先有蛋问题(chicken-and-egg problem)。我们需要路径的具体设计来计算 $G$,但没有 $G$ 我们又无法计算路径的级数 $N$。
一些常用结论
逻辑努力是大略估计电路延迟的有效方法。
CMOS 中 NAND 门通常比 NOR 门快(PMOS 比 NMOS 慢,串联比并联慢;NAND 中 PMOS 并联而 NOR 中 PMOS 串联)。
工程上,某路径上的最佳级努力为 $\sim 4$。
路径延迟通常对级数与尺寸不敏感(延迟曲线在最优点附近较平)。
级数小并不意味着延迟低,最佳级数通常是 $\log_4 F$。
驱动大电容时,反相器和 2 输入 NAND 通常延迟较小。